在学习神经网络之前,我们先了解一些简单的基础知识,我们以线性回归(预测)和softmax回归(分类)为例,了解简单的神经网络架构,数据处理,制定损失函数和如何训练模型。
线性回归
为了解释线性回归,我们举一个实际的例子:我们希望根据房屋的面积(平方米)和房龄(年)来估算房屋价格(元)。为了开发一个能预测房屋价格的模型,我们需要收集一个真实的数据集。这个数据集包括房屋价格、面积和房龄。在机器学习的术语中,该数据集称为训练数据集(training dataset)或训练集(training set)。每行数据(比如一次房屋交易相对应的数据)称为数据样本(sample),也可以称为数据点(data point)或数据实例(data instance)。我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
线性模型
假设自变量x和因变量y之间的关系是线性的,即y可以表示x中的元素的加权和,这里通常允许包含一些噪声,在上图体现就是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下式:

W称为权重(weight),权重决定了每个特征对我们预测值的影响。b称为偏置(bias)、偏移量(offset)或截距(intercept)。偏置是指当所有特征都取值为0时,预测值应该为多少。即使现实中不会有任何房屋的面积是0或房龄正好是0年,我们仍然需要偏置项。如果没有偏置项,我们的模型的表达能力将受到限制。严格来说,式(3.1)是输入特征的一个仿射变换(affine transformation)。仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项进行平移(translation)。
给定一个数据集,我们的目标是寻找模型的权重w和偏置b,使得根据模型做出的预测大体符合数据中的真实价格。输出的预测值由输入特征通过线性模型的仿射变换确定,仿射变换由所选权重和偏置确定。
而在机器学习领域,我们通常使用的是高维数据集,建模时采用线性代数表示法会比较方便。这个过程中的求和将使用广播机制。给定训练数据特征X和对应的已知标签y,线性回归的目标是找到一组权重向量w和偏置b:当给定从X的同分布中抽样的新样本特征时,这组权重向量和偏置能够使新样本预测标签的误差尽可能小。
虽然我们确信给定x预测y的最佳模型是线性的,但我们很难找到一个理想的数据集。所以无论我们使用什么方式来观测征X和标签y,都可能会出现少量的观测误差。因此,即使确信特征与标签的潜在关系是呈线性的,我们也会加入一个噪声项以考虑观测误差带来的影响。
损失函数
我们要考虑模型拟合程度的度量,这时候就要考虑损失函数(loss function),他可以量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差函数。
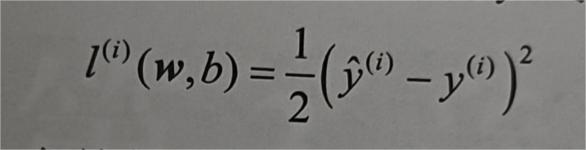
常数不会带来本质区别,但是形式上会更简单一些,对损失函数求导后常数系数为1
由于平方误差函数中的二次方项,估计值j(i)和观测值y(2)之较大的差距将导致更大的损失。为了度量模型在整个数据集上测质量,我们需计算在训练集n个样本上的损失均值(等价求和)

在训练模型时,我们希望寻找一组参数,这组参数能最小化在所有训练样本上的失,如下式

更新模型
为了寻找最佳的W和b,我们除了需要模型质量的度量方式,还要一种能够更新模型以提高模型预测质量的方法
解析解
线性回归恰好是一个很简单的优化问题,它的解可以用一个式子简单表示,这类解叫做解析解。我们先将偏置b合并到参数w中,合并方法是在包含所有参数的矩阵中附加一列。我们的预测问题是最小化|y-Xw|的平方。这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小值点。将损失关于w的导数设为0,得到解析解:
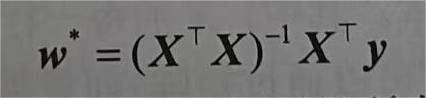
像线性回归这样的简单问题存在解析解,但并不是所有问题都存在解析解。解析解可以进行很好的数学分析,但解析解对问题的限制很严格,导致它无法广泛应用在深度学习中。
随机梯度下降
即使在无法得到解析解的情况下,我们也可以有效地训练模型。在许多任务中,那些难以优化的模型效果会更好。
梯度下降的最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。但实际中的执行可能会非常慢,因为在每次更新参数之前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体叫作小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们先随机抽取一个小批量B,它是由固定数量的训练样本组成的;然后,计算小批量的损失均值关于模型参数的导数(也可以称为梯度);最后,将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
我们用下面的数学公式来表示这一更新过程:
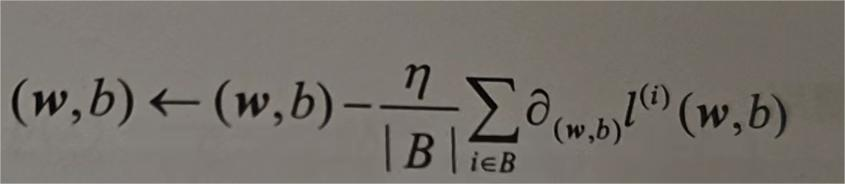
简单来说,该算法第一步是初始化模型的参数的值,如随机初始化,第二步是从数据集中随机抽取小批量样本且在负梯度方向更新参数,并不断迭代这一过程。对于平方损失和仿射变换,我们可以明确写成如下形式:
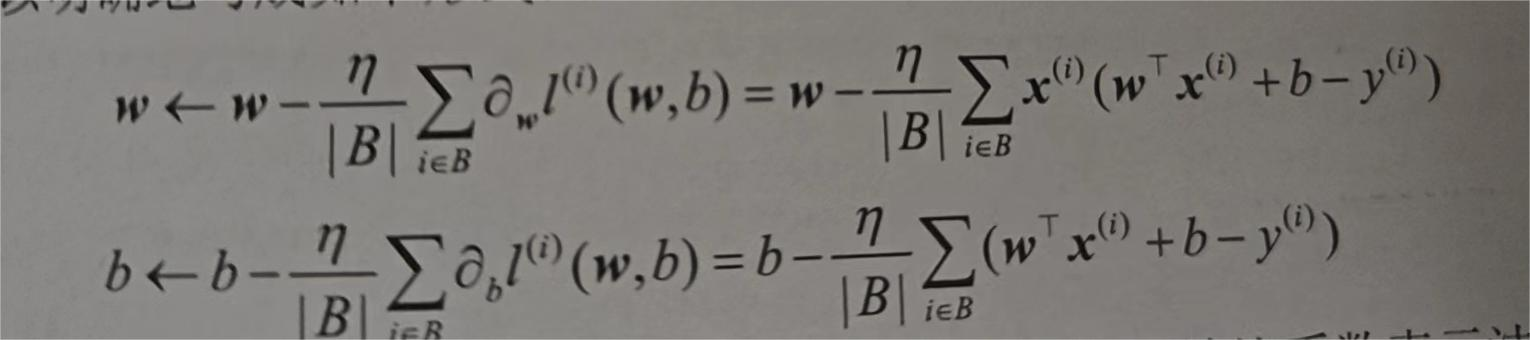
|B|表示每个小批量中的样本数,也称为批量大小(batch size)。η表示学习率(learning rate)。批量大小和学习率的值通常是预先手动指定,而不是通过模型训练得到的。这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。调参(hyperparametertuning)是选择超参数的过程。超参数通常是我们根据训练迭代结果来调整的,而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
在训练了预先确定的若干迭代次后(或者直到满足某些其他停止条件后),我们记录下模型参数的估计值,表示为w,b。但是,即使我们的函数确实是线性的且无噪声,这些估计值也不会使损失函数真正地达到最小值,因为算法会使损失向最小值缓慢收敛,但不能在有限的步数内非常精确地达到最小值。
线性回归恰好是一个在整个域中只有一个最小值的学习问题。但是对像深度神经网络这样复杂的模型来说,损失平面上通常包含多个最小值。深度学习实践者很少会花费大力气寻找这样一组参数,使在训练集上的损失达到最小值。事实上,更难做到的是找到一组参数,这组参数能够在我们从未见过的数据上实现较小的损失,这一挑战称为泛化(generalization)。
代码实现
在基本了解线性回归模型后,我们可以尝试用代码的形式体现。
从零开始实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
| import random
import torch
def synthetic_data(w, b, num_examples):
"""Generate y = Xw + b + noise."""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
def data_iter(batch_size, features, labels):
"""Iterate through a dataset."""
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
def linreg(X, w, b):
"""The linear regression model."""
return torch.matmul(X, w) + b
def squared_loss(y_hat, y):
"""Squared loss."""
return (y_hat - y.reshape(y_hat.shape))**2 / 2
def sgd(params, lr, batch_size):
"""Minibatch stochastic gradient descent."""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0],'\nlabel:', labels[0])
batch_size = 10
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
lr = 0.03
num_epochs = 10
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y)
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print(f'error in estimating w: {true_w - w.reshape(true_w.shape)}')
print(f'error in estimating b: {true_b - b}')
|
借助框架实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
next(iter(data_iter))
net = nn.Sequential(nn.Linear(2, 1))
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
w = net[0].weight.data
print('error in estimating w', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('error in estimating b', true_b - b)
|
相信看到这里你应该对线性回归有简单的认识了。